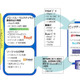
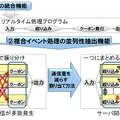
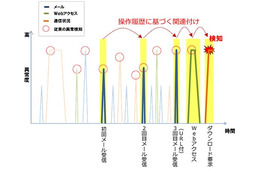
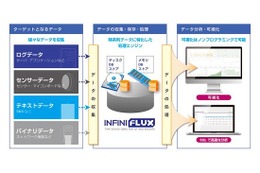
富士通研究所は20日、業界で初めて、ビッグデータと呼ばれる多種大量の時系列データ処理を統合的に開発・実行する環境を開発したことを発表した。 ビッグデータを処理するために、蓄積された大量データを処理するHadoopなどの並列バッチ処理技術や、到着したイベントデータをリアルタイムに処理する複合イベント処理技術が利用されているが、各処理技術に対応する開発・実行環境は統一されていなかった。 今回富士通研では、蓄積データ処理と、複合イベント処理のそれぞれの処理記述言語を統合的に扱える開発・実行環境を開発。この技術は(1)開発言語に依存せず簡単にプログラムの自動生成をする開発・実行環境の統合機能と、(2)複合イベント処理プログラムの処理効率を自動的に向上させる並列性抽出機能の2つから構成されている。 また、複合イベント処理の処理効率を自動的に向上させる並列性抽出機能も内蔵しており、複合イベント処理の処理記述から並列性を抽出して、適切な機能の組合せを推奨する技術により、高効率な並列アプリ設計が容易に実現できるという。 これにより分析処理からイベント処理までの開発期間を、約5分の1に短縮することを可能にした。具体的な事例としては、POS分析に基づくクーポン発行で、8週間から1.5週間に短縮できたとのこと。また各処理のパラメーターをプログラミングなしで容易に変更できるため、分析結果から得た知見を素早くイベントの検出条件に反映するなど、開発環境における試行錯誤を容易に行うことができる見込みだ。今後は、より機能を充実させ、ビッグデータ向けプラットフォームやミドルウェアにおいて2013年度の製品化を目指す。