※本サイトはアフィリエイト広告を利用しています
瑞原明奈選手や伊達朱里紗選手がアクリルスタンドプレゼント(PR))

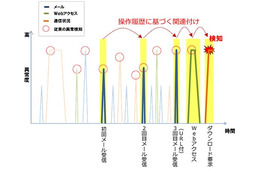
サイバーエージェント、ブラウザ向け音声ライブラリ「boombox.js」をOSSとして公開

「an」きゃりーCMを音声認識……スマホ番組表アプリ「Gガイドモバイル」でキャンペーン




 サイバーエージェント、ブラウザ向け音声ライブラリ「boombox.js」をOSSとして公開
サイバーエージェント、ブラウザ向け音声ライブラリ「boombox.js」をOSSとして公開
 「an」きゃりーCMを音声認識……スマホ番組表アプリ「Gガイドモバイル」でキャンペーン
「an」きゃりーCMを音声認識……スマホ番組表アプリ「Gガイドモバイル」でキャンペーン
 Apple CarPlayが日本のカーナビ市場にもたらすインパクト
Apple CarPlayが日本のカーナビ市場にもたらすインパクト
 【NTT R&Dフォーラム2014 Vol.6】360度ライブ映像配信や雑談対応音声応答など身近な技術も多数
【NTT R&Dフォーラム2014 Vol.6】360度ライブ映像配信や雑談対応音声応答など身近な技術も多数
 NTT、スマホを高音質ワイヤレスマイクとして使える新技術……テレビ会議などに活用可能
NTT、スマホを高音質ワイヤレスマイクとして使える新技術……テレビ会議などに活用可能
 「Google Chrome 32」を公開……タブで音声を探す
「Google Chrome 32」を公開……タブで音声を探す
 オトバンクと情報工場、音声版・電子版の書籍ダイジェストを配信
オトバンクと情報工場、音声版・電子版の書籍ダイジェストを配信
 サムスン、音声ガイドを充実させた視覚障害者支援スマートフォン「Galaxy Core Advance」
サムスン、音声ガイドを充実させた視覚障害者支援スマートフォン「Galaxy Core Advance」