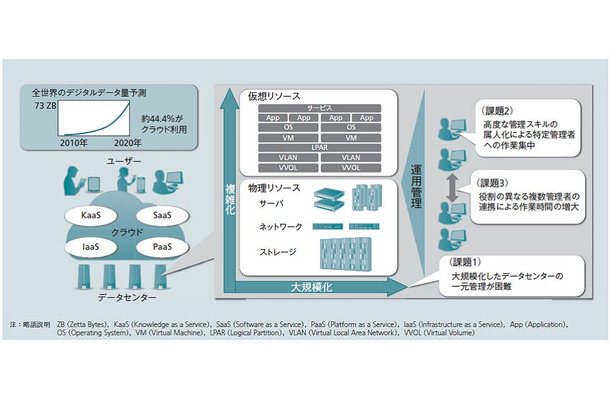
データセンターの大規模・複雑化により,管理者には従来に増して高度な知識や豊富な経験が求められている。しかし,各企業では経験が十分な管理者を,必要な人数だけ確保できない場合が多い。こうしたことは,運用管理作業の中で特に迅速な対応が求められる障害復旧作業を困難にする。障害に迅速に対応するためには,障害発生から回復までのサイクルのうち,障害検知から原因特定までに要する時間を短縮することが重要である。そこで障害発生時に原因を解析するためのRCA(Root Cause Analysis:障害原因解析)技術を開発した。
クラウドでは,利用者が利用したいときに,迅速にITリソースを割り当てられることが求められている。しかし,大規模データセンターでは,複数人の管理者が分業して管理を行っているため,ITリソースを割り当てるために,企業によっては,社内ワークフローを使い,管理者間で連携して作業を実施する必要がある。例えば,IaaS(Infrastructure as a Service)のような仮想サーバを提供するようなサービスの場合,仮想サーバと,データの格納先のストレージを提供するのに,仮想サーバ管理者とストレージ管理者が連携して,システム構築を行っていた。その結果,人間が介することで,クラウドで要望される迅速なサービス提供が困難であった。
この三つの技術の共通点は,すべて管理業務を省力化する点である。大規模・複雑化が進むデータセンターの運用管理コストを削減するためには,管理者が頻繁に行う管理業務の省力化が重要である。今後は,さらなる管理業務の省力化を図っていく予定である。なお,ここで紹介した技術は,日立運用管理ソフトウェア「Hitachi Command Suite」,「Hitachi IT Operations」へそれぞれ適用され,製品化されている。